朱子學では「事物には皆その在り方を規定する理があり、その事物の理を窮め知ること」を窮理と言ふ。そして「理を窮めるには『一木一草』の理に至るまでいちいち全部知り盡くす必要があるが、さういふ努力を積み重ねれば、或る段階で『豁然(かつぜん)貫通』して、すべての理を一擧に了解し得る」ものとした。
この小欄が、文字文化の「一木一草」たらんことを祈る。
紹 継
「わいうえおじず」から始める歴史的仮名遣ひ
佐藤正彦
歴史的仮名遣ひに関心はあっても、実際に自分で文書を作るとなると、ためらふ方も多いと思ひます。
「~てゐる」「~と思ふ」「~だらう」といふ表現になじんでゐても、
全ての単語に対して常に歴史的仮名遣ひを意識しながら文章を作るのは、
相応の知識が必要だと思ってゐるかもしれません。
しかし、それは取り越し苦労です。単語に対して仮名遣ひを意識するのでなく、
仮名文字に対して仮名遣ひを意識することで、今すぐ歴史的仮名遣ひの文章を作れるやうになります。
最初に現代仮名遣ひと歴史的仮名遣いの対照表を紹介します。
| 現代仮名遣ひ | わ | い | う | え | お | じ | ず | oう | yuう | yoう | (か) | (が) | (aお) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 歴史的仮名遣ひ | い | う | え | お | じ | ず | oう/oふ | yuう/yuふ | yoう | (か) | (が) | (aお) | |
| 〃 | わ | ゐ | ゑ | を | ぢ | づ | aう/aふ | yaう | (くゎ) | (ぐゎ) | (aを) | ||
| 〃 | は | ひ | ふ | へ | ほ | iう/iふ | eう/eふ | (aほ)/(aふ) |
上記の表を見て、やはり変換規則が複雑だと思はれるかもしれません。
ただ、全てを知った上で、歴史的仮名遣ひ文の作成が容易だといふことを理解してもらひたかったので、あへて全ての規則を紹介しました。
この中で括弧書きになってゐる「か」「が」「aお」は忘れてかまひません。通常の漢字仮名交じり文ではまづ使ひません。
「か」「が」が「くゎ」「ぐゎ」になるのは、漢字の音読みを仮名書きしたときだけです。
例へば、「お菓子」を「おくゎし」と書くときです。子供用の絵本を除き、仮名書きすることは通常ありません。
次に、「aお」が「aふ」になるのは、「仰(あふ)ぐ」「倒(たふ)す」など例外的な音韻変化を起こしたもので、
個別に覚えることで解決します。これらも仮名書きすることは通常ありません。
さうなると、仮名として意識すべきものは「わいうえおじず」の7個に限られます。
「う」の場合は直前の仮名文字も含めて、置き換へる場合がありますが、
「う」が後ろに来なければ、7個以外の仮名は意識する必要はありません。
それでは、歴史的仮名遣ひの文章を簡単に作る手順を示します。
ここでは実例として内閣訓令『現代仮名遣ひ』の前書きを使ひます。
(内閣訓令は著作権保護の対象外なので引用例として使ひました。)
「わいうえおじず」を赤字で示します。実際に編集を行ふ作業では、
各自が好みのエディターアプリを使ひ、検索したりハイライト表示をしてください。
8 歴史的仮名遣いは,明治以降,「現代かなづかい」(昭和21年内閣告示第33号)の行われる以前には,社会一般の基準として行われていたものであり,今日においても,歴史的仮名遣いで書かれた文献などを読む機会は多い。歴史的仮名遣いが,我が国の歴史や文化に深いかかわりをもつものとして,尊重されるべきことは言うまでもない。また,この仮名遣いにも歴史的仮名遣いを受け継いでいるところがあり,この仮名遣いの理解を深める上で,歴史的仮名遣いを知ることは有用である。付表において,この仮名遣いと歴史的仮名遣いとの対照を示すのはそのためである。
順番に置き換へていきます。
- 「仮名遣い」→「仮名遣ひ」、「かなづかい」→「かなづかひ」、「行われ」→「行はれ」、「言う」→「言ふ」:ワア行五段活用動詞の活用語尾は、ハ行になります。
- 「いた」→「ゐた」、「いる」→「ゐる」:存在を表す動詞「いる」は、「ゐる」となります。各活用形もそれに倣ひます。
- 「おいて」→「おいて」:「おく」は歴史的仮名遣ひでも「おく」のままです。
- 「おいて」→「おいて」、「継いで」→「継いで」:連用形のイ音便です。「い」はそのままです。
- 「深い」→「深い」、「ない」→「ない」:形容詞の活用語尾「い」はそのままです。これは文語の活用語尾「~き」→「~い」の変化なので、イ音便の一種です
- 「かかわり」→「かかはり」:個別に覚えますが、語中の「わ」はほとんどの場合「は」になり、「かかわる」と「かかえる」は派生関係にあると思はれ、「わる・える」の組は「はる・へる」になる規則があるので、覚えやすい例です。
文法規則に基づくものが3個、個別に覚えるものが「ゐる」「おく」「かかはり」の3個になります。 これで歴史的仮名遣ひの文章が出来上がります。下記の文章は、仮名を置き換へたものを青字で、 置き換へる必要がなかったものを緑字で表してゐます。
8 歴史的仮名遣ひは,明治以降,「現代かなづかひ」(昭和21年内閣告示第33号)の行はれる以前には,社会一般の基準として行はれてゐたものであり,今日においても,歴史的仮名遣ひで書かれた文献などを読む機会は多い。歴史的仮名遣ひが,我が国の歴史や文化に深いかかはりをもつものとして,尊重されるべきことは言ふまでもない。また,この仮名遣ひにも歴史的仮名遣ひを受け継いでゐるところがあり,この仮名遣ひの理解を深める上で,歴史的仮名遣ひを知ることは有用である。付表において,この仮名遣ひと歴史的仮名遣ひとの対照を示すのはそのためである。
しかしながら、上記の例だけでは重要な変換規則がまだ含まれてゐないので、他の例も加へます。
3 この仮名遣いは,科学,技術,芸術その他の各種専門分野や個々人の表記にまで及ぼそうとするものではない。
6 この仮名遣いは,「ホオ・ホホ(ホホ)」「テキカク・テッカク(的確)」のような発音にゆれのある語について,その発音をどちらかに決めようとするものではない。
- 「仮名遣い」→「仮名遣ひ」:ワア行五段活用動詞の活用語尾は、ハ行になります。
- 「及ぼそう」→「及ぼさう」:推量の助動詞「う」が後ろに付いたオ段の仮名は、ア段の仮名に置き換へます。
- 「のように」→「のやうに」:助動詞「ようだ」の「よう」は語源が「様」なので、その字音「やう」になります。
- 「ついて」→「ついて」:連用形のイ音便です。「い」はそのままです。
- 「決めよう」→「決めよう」:上一段、下一段、カ変、サ変の各動詞に付く推量の助動詞「よう」は、そのままにします。
- 「ない」→「ない」:形容詞の活用語尾「い」はそのままです。イ音便の一種です。
文法規則に基づくものが5個、個別に覚えるのが「やうだ」の1個です。歴史的仮名ひの文章を下記に示します。
3 この仮名遣ひは,科学,技術,芸術その他の各種専門分野や個々人の表記にまで及ぼさうとするものではない。
6 この仮名遣ひは,「ホオ・ホホ(ホホ)」「テキカク・テッカク(的確)」のやうな発音にゆれのある語について,その発音をどちらかに決めようとするものではない。
文法規則に基づくもの
下記に紹介するものは、文法規則により全ての場合に当てはまるので、必ず覚えませう。
| 現代仮名遣ひ | 書こう | 嗅ごう | 貸そう | 勝とう | 死のう | 浮ぼう | 噛もう | 狩ろう | 買おう |
|---|---|---|---|---|---|---|---|---|---|
| 歴史的仮名遣ひ | 書かう | 嗅がう | 貸さう | 勝たう | 死なう | 浮ばう | 噛まう | 狩らう | 買はう |
五段活用動詞の活用語尾につながるときは、オ段+「う」の形になります。ア段+「う」に置き換へます。ただし、「~おう」のときは「~あう」ではなく「~はう」に置き換へます。
| 現代仮名遣ひ | 良かろう | ~だろう | ~たろう | ~でしょう | ~ましょう |
|---|---|---|---|---|---|
| 歴史的仮名遣ひ | 良からう | ~だらう | ~たらう | ~でせう | ~ませう |
形容詞・形容動詞・助動詞の活用語尾につながるときは、「~ろう」「~しょう」のどちらかの形になります。それぞれ、「~らう」「~せう」に置き換へます。
| 現代仮名遣ひ | 買わ~ | 買い~ | 買う | 買え~ | 買おう |
|---|---|---|---|---|---|
| 歴史的仮名遣ひ | 買は~ | 買ひ~ | 買ふ | 買へ~ | 買はう |
五段活用の活用語尾がワ行のときは、同じ段のハ行に置き換へます。ただし、「~おう」のときは「~ほう」でなく、「~はう」に置き換へます。
| 現代仮名遣ひ | 書いて | 嗅いで | 下さい | 良い |
|---|---|---|---|---|
| 歴史的仮名遣ひ | 〃 | 〃 | 〃 | 〃 |
| (音便前) | 書きて | 嗅ぎて | 下さり | 良き |
イ音便はそのまま「い」にします。「下さる」「ござる」「なさる」などのラ行五段活用動詞に「~ます」がつながると、 「~ります」から「~います」に変るときがあります。これもイ音便の一種です。 形容詞の終止形語尾は「い」は、文語の連体形語尾「~き」がイ音便で「~い」になったものです。
| 現代仮名遣ひ | 買(こ)うて | 請うて | 良う | 無(の)う | 大きゅう | 美しゅう | 薄う |
|---|---|---|---|---|---|---|---|
| 歴史的仮名遣ひ | 買(か)うて | 〃 | 〃 | 無(な)う | 大きう | 美しう | 〃 |
| (音便前) | 買(か)ひて | 請ひて | 良く | 無(な)く | 大きく | 美しく | 薄く |
ウ音便はそのまま「う」にします。ただし、直前の仮名文字が置き換はる場合があります。音便前の連用形から適切な仮名を選んでください。
個別に覚えるもの
下記に紹介するものは、使用頻度が高いので、文章を書いてゐるうちに覚えてしまひませう。
| 現代仮名遣ひ | そうだ | ようだ | ~ず | ~まい | ~よう | ~ていく | ~ている | ~ておく | ~ておる |
|---|---|---|---|---|---|---|---|---|---|
| 歴史的仮名遣ひ | さうだ | やうだ | 〃 | 〃 | 〃 | 〃 | ~てゐる | 〃 | ~てをる |
| 現代仮名遣ひ | ~ぐらい | ~さえ | ~ずつ | なお、 | まず、 | こう | そう | どう |
|---|---|---|---|---|---|---|---|---|
| 歴史的仮名遣ひ | ~ぐらゐ | ~さへ | ~づつ | なほ、 | まづ、 | かう | さう | 〃 |
最後に、上一段活用動詞「~いる」「~じる」、下一段活用動詞「~える」の場合、それぞれ「い」「じ」「え」に複数の仮名候補があります。 上一段活用は所属動詞数が少なく、覚える動詞は少数です。下一段活用も派生動詞を手掛かりに仮名を絞り込めます。 しかし、詳細を述べるのは、本稿の目的でないので、別の機会とします。
| 現代仮名遣ひ | ~いる | ~える | ~じる |
|---|---|---|---|
| 歴史的仮名遣ひ | ~いる | ~える | ~じる |
| 〃 | ~ゐる | ~ゑる | ~ぢる |
| 〃 | ~ひる | ~へる |
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(6)
黒田信二郎
編集・制作サイドに求められる文字処理
『平成基本漢字字形表』『和字正濫鈔』の制作におけるEPUB実装環境における文字処理は、具体的には「JIS漢字範囲」×「Unicode範囲」×「文字図形番号対応」を整理する作業で、『今昔文字鏡』の 文字図形番号[*1]が重要な役割を果たしている。
一般的に、編集・制作サイドが受領する原稿・テキストは様々であるが、大きく以下の二つに分けられる。
1)著訳者・翻刻者が自ら入力したテキスト
この場合、提供されたテキストの入力環境のフォント実装レベルを把握し、どの範囲で文字が使用されているかを知ることが必要で、それをEPUB環境でどう実現するかを検討する。入稿は概ね「現代通用字」であるが、テキストの内容によっては「こだわり字(字形表示上区別を要する)」があるので確認しておく。著訳者・翻刻者にその部分を「文字図形番号」で指定してもらえれば一意に字形が定まるので処理がしやすい。また、入稿がWordやExcelであれば、テキスト内の文字鏡文字を文字鏡番号(文字図形番号)に一括変換してくれるフリーソフトWord 文字鏡変換 も公開されており、作業効率上重要なポイントなる。(なお、入稿テキストに文字鏡TTF文字が直接埋め込められている場合には、編集・制作サイドの環境にも「文字鏡TTFフォント」が実装されている必要がある)
2)既製の印刷書籍(あるいは手稿原稿)のテキスト化
印刷形態あるいは手稿原稿と完全に同じ字形で表示するべきとの「こだわり字」がどこまで必要かの判断を要する。印刷データ(DTP)からのテキスト抽出、OCRでの誤変換チェック、テキスト再入力など、どれも作業負荷は高いが、印刷書籍の場合は基本的に制作過程で編集・文選(活字の選定)のチェックが入っているので、その中から「こだわり字」を抽出し対応する必要がある。OCRは現状主にShift-JISベース変換なので、誤変換・変換不能箇所のチェックで洗い出せることが多く、フォント実装対応が保証できない文字は「文字図形番号」に置き換える。
Unicode処理とEPUB実装環境
日本語テキスト、とりわけ多漢字コンテンツのEPUB化において、各EPUB3の主要リーディングシステム(RS:電子書籍端末のアプリケーション)の実装環境が前提となるが、「JIS漢字」以上のフォントの実装については必ずしも保証されておらず、基本は「JIS漢字」となる。そしてコンピュータ上の文字情報交換の基盤であるUnicodeをどのように扱うかを考える必要がある。
EPUB3とUnicodeの関係では、従前より「JIS漢字のUnicodeサロゲートペア領域文字」と「Unicode IVS(Ideographic Variation Sequence/Selector)の文字」について議論されてきた。それは、EPUB RS内にUnicode対応フォントの実装がないか、あるいはRSがIVS非対応である問題で、現状ではまだ課題が残る。一方、一部RSではUnicodeの「統合漢字領域」まで表示が出来る場合もあり(明朝体フォントに対応がなくゴシック体が表示されることもある)、かえってデータ制作側の混乱を招いているのが現状であろう。
この混乱に対して、「JIS漢字範囲」×「Unicode範囲」×「フォント実装」の関係を、4パターンに整理してみた。
①Unicodeコードポイントで精確に表示できる文字いずれにしても「文字へのこだわり」があるコンテンツでは、相当な注意を払ったうえで、必要に応じて「文字図形番号+SVG画像フォント」の手法を用いることで解決が図れる。
・通常のコードポイントと「JIS漢字」の例示字形が一致対応している。
②Unicodeにコードポイントがあり「JIS漢字」内であるが、RSの実装フォントセットでの表示上、表示ができなかったり字形に揺れが生じる文字
・いわゆるサロゲート文字問題はほとんど解決しているが、Unificationで異なる字形に同一のコードが当てられていて、後にIVSで切り分けられた文字など、事情に精通していないと混乱するケースはまだ残る。またフォントセットのデザイン方針の差異によるものもある。
③Unicodeにコードポイントがあるが、「JIS漢字」にない文字
・デスクトップPCのIMEでは「環境依存文字」などとしてUnicode文字の表示範囲は拡張されるが、最終的にはフォント実装環境に依存するので、すべてのUnicode文字表示が保証されるわけではない。
・EPUB3の要求する最低フォント実装が「JIS漢字」なので、個々にいろいろな環境・方法があるとしても、割り切って「図形番号」を使うほうが安心である。
④Unicodeにコードポイントがない文字
・コード処理が出来ないので「図形番号」を使う。
まずなにより、編集・制作の過程で著訳者・制作会社などとの間で連絡をとりあう際に「一意に字形が決められる番号」でお互いにやりとりができると、作業上のストレスがなくなる。あらかじめ入稿テキストの中に「&M012345;」が指定されれば字形は確定するし、電話やメールで「そこは『&M012345;』の文字にします」と言われれば、それで解決する。それぞれが独自の管理番号をふったり、ローカルエリアに割りふると互換性がなくなるが、文字図形番号との参照マクロを作成すれば解決する。
理想的には、クラウド上に出版用多漢字処理の 「文字図形共有基盤」サイトを置き、その字形が文字コード上どういう位置にあるかに関わりなく、必要な文字を編集・制作のみならず、著訳者から読者にいたる誰でもが検索し、使える環境であろう。これを利用して制作されたテキストをどういう環境にどうアジャストさせ、コード処理するかはあくまで編集制作サイド内部の技術領域の問題ではないか。 「現代日本の通用字形」を「JIS漢字(JIS X 0213:2004)JIS第1~第4水準」とし、それを超える無限ともいえる利用頻度の低いロングテールの文字は、いったん文字図形番号の集合の中で処理したほうが、全体としての作業効率が向上する。
「EPUB用文字鏡明朝文字」SVG画像フォント126,000字の作成
これまで文字文化協會では『シャーロックホームズの冒険』(「正字・正仮名」新訳原稿)の電子書籍版刊行を嚆矢として、SVG文字実装を経験してきたが、今回はSVG利用に下記のいくつかの改善、検証を試みた。
*文字鏡明朝文字のウエイトを調整し、各種EPUBのRSが表示する明朝体との違和感をできるだけ解消するため「EPUB用文字鏡明朝文字」SVG画像フォント(中太)126,000字[*2]を作成した。ただ1画から84画までの文字を一律に処理するのには無理があり、画数などから判断して、さらにボールド処理をかけたほうがきれいに表示される。
*「EPUB用文字鏡明朝文字」SVG画像フォントについて、個々のボールド処理、色処理、カコミ処理のRS上の表示を確認した。但し、各RSのビューワー環境での表示には誤差が生じる場合があり、課題は残っている。
*SVG画像フォントを「画像参照方式」ではなく、フォントデータを直接本文テキストに書き込み、SVGデータ内に検索用テキストを埋め込んでおけば一部のRS上では検索が可能な事を確認した(但し、画面表示上、横書きのベースラインのずれ、縦書きの文字上下に不自然なスペース発生するので、現時点でこの方式の採用は限定される)。また、この方式では単漢字の検索のみとなる。
検索用テキストについてはRSの検索機能を利用するので、とりあえず「代理基本文字(JIS漢字)」とするか、なければUnicodeの文字にするか、さらに「検索語」として熟語(見出し文字列など)漢字列にするかの検討を行なった。「表示」と「検索」の両方のニーズに対応するためには、今後この種のテーブルの充実もさらに進める必要がある。
『平成漢字基本字形集』の具体的実装[*3]
・字形集の表の入稿データはEXCELで構築されていたが、辞書的なコンテンツを辞書専用ではなく汎用的なEPUB3のRSで実装することを基本とした。
・EXCELデータ内の文字を、「通用JIS漢字」、「JISにないUnicode文字」「Unicodeにない文字図形番号」に区分し、それぞれ入稿データを精確に反映する字形表示が可能となるよう対応した。
・基本見出し字8,500字に「EPUB用文字鏡明朝文字」SVG画像フォントをSVG画像参照方式で採用し、見出し字形デザインの統一を意図した。
・解説などの記述も含め、Unicodeにない文字字形が1,782字種、Unicodeにあるが「JIS漢字」範囲にないものが956字種あり(Unicode⇒文字図形番号の変換マクロを作成して一括変換)、いずれも1文字単位でSVG画像フォントを用いた。
・電子書籍ならではの検索に配慮し、検索対象となる部分には「JIS漢字」範囲の通用字を用いている。またリンク機能を活用し、索引にリンク(約13,000リンク)をはり、利用者の便の向上を図った。
・コンテンツ全体のデータサイズは約27メガバイトで、現在のRSの端末機器のスペックによって、データの読み込み時間、リンク・検索のレスポンスに課題が残るが、いずれスペックの向上により解決が見込まれる。
『和字正濫鈔』の具体的実装
・和字正濫鈔序の漢文、書き下し文と二巻~五巻で「いろは順」に並べられた語の「見出し漢字」について、『今昔文字鏡』文字からできるだけ原典に忠実な字形を採用し、「EPUB用文字鏡明朝文字」SVG画像フォントで表示した。原典の漢字字形は楷書的なものからくずし字まで多様であり、一部推測や別資料で字形を確定したものもある。 ・本文の仮名についての翻刻は変体仮名についても通用仮名で統一した。 ・検索の利便のために「文字鏡基本文字情報・関連字情報」などを参考にSVG画像フォント部分に可能な限り「JIS漢字」「Unicode文字」規格対応の註記をつけた(なお「国字」については、対応規格字形の無いものがある)。これにより、文字表示は原本に対応した字形だが、註記によってRS上での検索対象範囲を広げることを意図した。 ・梵字実装作業 ・解説原稿に梵字五十音図があり、表示には『梵字鏡』文字図形番号と梵字SVGフォントを利用した。
-------------------------------------------[*1]『今昔文字鏡』の「文字図形番号」は下記のサイトで公開されている。また大修館書店『大漢和辞典』収載の範囲内は概ね「大漢和番号」と同じである。
*情報処理学会試行標準IPSJ-TS 002:2014「文字図形識別情報」[*2] 126,000字は、『今昔文字鏡』明朝体漢字のなかで、主に日本語の学術出版用途で必要と判断されるものとしたが、まだ未収載の漢字も多くあり順次登録の必要がある。また、どうしてもRS実装明朝体とデザインの統一を求められる場合、文字利用ライセンスで『今昔文字鏡』明朝を字母としてフォントを作成することも可能である。
https://www.itscj.ipsj.or.jp/ipsj-ts/ts02-2014/charsp-id.htm#6.
⇒6.文字図形集合の一覧(SVG画像フォント)
a)文字図形番号順
b)部首・部首内画数順
*ISO/IEC10036 Registration Authority for Font-related Objects
http://10036ra.org/
⇒Registry MOJIKYO
[*3]実装の作業は多漢字処理に実績のある有限会社ワイズネットに委託した。
http://www.yznet.co.jp/
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(5)
黒田信二郎
『平成漢字基本字形集』と『和字正濫鈔』の電子書籍、いよいよ刊行へ
長らくデータ構築を行っていた現代の『干祿字書』を目指す 『平成漢字基本字形集』は5,700種8,500字の整理を終え、EPUBデータ化の段階にはいり、2016年9月の刊行を目指すことになった。また、江戸時代に僧契沖が古文献によって仮名遣いを研究し、後に「歴史的仮名遣い」確立の基盤となった『和字正濫鈔』についても、原本画像との対比を基本としたEPUB版の刊行を、同時期に予定している。
これらの2点は、EPUB漢字表示に「文字鏡SVG画像フォント」を駆使するものだが、その具体的な制作報告を2回にわけて行いたい。
文字への「こだわり」とは何か
日本語コンテンツの制作を企画する中で、通常の文字字形表現は原則「JIS漢字(JIS X 0213:2004)JIS第1~第4水準」、すなわち「現代日本の通用字形」で充分で、いわゆる新字・旧字の使い分けもかなりの文字が「JIS漢字内」で可能であるという意見は多い。それでは文字への「こだわり」とはどういうことなのか。これまで多漢字対応の議論の多くは、電子行政上の氏名表記とそれに伴うビジネスシーンで展開されてきた。一方、出版の世界では活字印刷の時代から制作過程で編集・文選作業が入っており、著訳者・翻刻者の意図としてのこだわり以外は、ほとんどが「活字」あるいは「フォント」選定の問題に起因すると考えられる。
それでも、たとえ1冊の本の中の数文字であっても著訳者・翻刻者の意図として「現代通用字形を超えた字形表示の区別を求めるこだわり」は当然あり、以下のような必要性を無視するわけにはいかない。
・文字字形に歴史的な考証を要するものこれらの場合、実装や例示フォント字形のゆれを無視したコード依存はできないし、そうかといってその部分をいつまでも印刷書籍時代の制作サイドのローカル作字(ローカル外字エリア)に依存していては、作業効率はもちろん、将来の文字データ処理環境の変化の際のデータ変換業務に大きな負荷がかかる。「青天井、底なし沼の漢字」を「こだわりをもって」扱うにあたって、将来起こり得る様々なアプリ環境、実装環境の変化に対して、データ変換処理対応を容易にするためには、 文字図形番号 による一意の図形同定が著訳者から読者につながる共有基盤として必須のものである。
・固有名詞(歴史的人名・地名・物の名前)など唯一無二を表わすもの
・文字字形のもつ雰囲気などで、表現上の創意や文章への嗜好を示すもの
・部分的に複数の字種(甲骨文字・梵字など)、書体(篆書・草書など)を使い分けるもの
・正體字に忠実であるべきとの考えに基づくもの
現段階で有効な文字図形番号共有とSVG画像フォント
前回も述べ、そしてもっとも強調したいことが、EPUB3実装基本の「JIS漢字」範囲で表示しきれない文字表示については、1文字ごとに「標準化された文字図形番号[*]を利用したSVG文字貼り付け」(文字図形番号+SVG画像フォント)という手法が、もっとも効率的かつ有効な方法であるということである。EPUB3の主要リーディングシステム(電子書籍端末のアプリケーション)では、SVG画像処理が可能となっている。
EPUB環境は電子書籍の汎用的立場を維持すべきものであり、日本語コンテンツの電子化の基礎に「JIS漢字」10,050字を実装範囲とすることには妥当性が認められる。実装範囲の拡張をそれぞれのリーデイングシステムがそれぞれ行なうと、制作側はかえって混乱するばかりとなる。今後の競争的課題の方向性は文字種の拡張より、フォント書体・デザインのバリエーションの拡張にあろう。
しかしながら、その歴史、地域、使用目的の多様性から20万字以上はあると推定される漢字に対する、原典の翻刻や、著訳者の文字表現へのこだわりに、何らかの対応が必要であることも確かである。つまり、「こだわりの文字」対応のために、EPUB環境での1文字処理の汎用的手法の開発が必要なのである。
次回は、「EPUB用文字鏡明朝文字」SVG画像フォントを参照方式で採用した『平成基本漢字字形表』と『和字正濫鈔』の制作にあたって、EPUB実装環境における「JIS漢字範囲」「Unicode処理」「文字図形番号対応」の具体的な作業について報告する。
(続く)
-------------------------------------------
[*1]「標準化された文字図形番号」は下記のサイトで公開されている。また大修館書店『大漢和辞典』収載の範囲内は概ね「大漢和番号」と同じである。
*情報処理学会試行標準IPSJ-TS 002:2014「文字図形識別情報」
https://www.itscj.ipsj.or.jp/ipsj-ts/ts02-2014/charsp-id.htm#6.
⇒6.文字図形集合の一覧(SVG画像フォント)
a)文字図形番号順
b)部首・部首内画数順
*ISO/IEC10036 Registration Authority for Font-related Objects
http://10036ra.org/
⇒Registry MOJIKYO
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(4)
黒田信二郎
『概説 康煕字典』の電子書籍化
2015年8月に刊行した、谷本玲大著訳『概説 康煕字典』は、DVD-ROM『康煕字典』(2007年2月 紀伊國屋書店発行、現在品切れ)の解説を底本とする電子書籍である。解説本はもともとワープロソフト「一太郎」(ジャストシステム)で執筆、レイアウトPDF化され、また本文は別にテキストファイルがあるという、制作側からしてみると極めて扱いやすいものであった。
著者は漢字文献情報処理学会編『電脳中国学 インターネットで広がる漢字の世界』(1999 好文出版)の執筆者の一人であり文字鏡研究会でも活躍されている、文字と文字コード・フォントに関して大変造詣が深い方であり、執筆に当たっての「文字表示」についての配慮(印刷版では文字鏡TTFフォントの張り込み)が行き届いた原稿だったのだ。
基本的に本文はUnicodeをベースとしたテキストであったので、電子版の文字の表示に関しては、EPUB3の基盤である「JIS漢字」の範囲にない文字約40字をチェックし、篆書体2字と併せて文字鏡SVG画像フォントを利用するための 文字図形番号
を入稿データ内に指定するという、大規模な変換用マクロに依存するまでもない作業であった。
現段階で有効な文字図形番号共有とSVG画像フォント
『康煕字典』の序文や凡例の現代語訳など漢字に関する専門的内容を含むテキストであっても、この範囲の外字対応作業で済むということは、基本文字セットの実装を「JIS漢字」範囲とし、そこで表示しきれない文字については「標準化された文字図形番号を利用したSVG文字貼り付け」という手法が、現段階でもっとも効率的かつ有効な方法であることが裏付けられたと考えられる。
実装や例示フォント字形のゆれを無視したコード依存はできないし、そうかといってその部分をいつまでも制作サイドのローカル作字に依存していては、作業効率はもちろん、将来の文字データ処理環境の変化の際のデータ変換業務に大きな負荷がかかることが予想される。精確な文字表示のやりとりをテキストベースで行うためには、いわゆる「機種依存文字」からの脱却が必要である。
印刷書籍では印刷所に対応フォントを作成してもらうことで当面の解決は図れるが、かつてJIS第1、第2水準がやっと一般化した時代のデータ交換のための「外字・異体字処理」は苦労の多いもので、ローカルで作字したものを画像やビットマップで貼りつけるか、無理やり表示可能な文字に置き換えるか、その文字の構成を説明する文章を付加するというような処理が行なわれていた。それらのテキストデータは、その後の文字コードや実装の拡張という環境変化の中で極めて扱い難いものとなってしまっている。青天井、底なし沼の漢字を扱うにあたっては、この教訓から何を学ぶかが大切なのである。
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(3)
黒田信二郎
正字・正假名原稿の電子化
文字文化協會では2015年3月に、『シャーロック・ホームズの冒険』の翻訳本を刊行した。有名なコナン・ドイルの原作を、翻訳家・兼武進氏が正字・正假名の文章で新たに訳しおろした12編の短編集で、シドニー・パジェットの挿絵も完全収録したものである。
なぜ、正字・正假名なのか
訳者は、ホームズ、ワトソンの名コンビが活躍した19世紀末のロンドンの雰囲気を、正字・正假名の格調高い語彙と文体で表現するという明確な意図をもって翻訳にあたっている。学生時代に福田恒存『私の國語教室』から啓発されたとして、本書「譯者あとがき」では次のように述べている。
この譯書の譯文はいささか古風な印象を與へるのではないかと思はれる。それは、しかし、譯者のあへて意圖したところである。今から百二三十年もの昔、英國で書かれた物語である。譯者としては讀者に、その時間の隔りを輕視するのではなくむしろ強く意識しながら物語を愉しんでもらふための方途として、古風な語彙や文體を散りばめてみた。そこから生れる違和感のゆゑに、ヨーロッパの世紀末に生きる私立諮問探偵ホームズの重層的な性格や當時の世相が一層きはだつてくるのではないかと考へた。
文章の表記で歴史的假名遣に從ひ、漢字は正字を用ゐたことも、譯文を古風に見せるのに一役買ふであらうと思ふ。この飜譯が、竝外れて推進力の強い物語で、そのことを證明する一助にでもなればと願つてゐる。
「契沖」データによる入稿
訳稿は、正統國語ソフト「契冲」を使って執筆された。
「契沖」(申申閣発行)はパソコンで正字・正假名文章を作成するためのワープロソフトで、文語文法とこれを継承する正統口語文法を取扱うために開発され、正漢字フォント『文字鏡契冲』が表示及び印字用に添附されている。開発者の市川浩氏はその意図を次のように挙げている。
○「ゐ」、「ゑ」が入力文字として使へること
○文語特有の用言の活用に對應ができること
○歴史的假名遣に不馴れでも正しく使へること
○正漢字と常用漢字の混淆が防げること
○同音異義語の書分けができること
このうち、「正漢字と常用漢字の混淆が防げること」については、
常用漢字の字體は略體の採用だけでなく、『舍』を『舎』とするなど意味の無い字形改變が至る所で行はれ、專門家以外殆ど通曉できず、JISでもそのすべてには對應してゐません。
また常用漢字の弊害である「同音の漢字の書換へ」や「交ぜ書き」を拒否し、「日食、改ざん」などを「日蝕、改竄」と正規の表記を可能にしてゐます。
としている。
EPUBデータ化の過程と文字処理
「契沖」に付いている明朝体フォントセット「文字鏡契冲」は、JIS漢字のコードポイントに該当文字の正字体フォントをあてることにより、正漢字を表示・印刷できる仕組みとなっている。従って、編集制作側が同じフォント環境を用意すれば、フォント名の指定を変えることで、訳者の意図が精確に表現された表示・印刷を一括して得ることが可能である。しかしながら、EPUB3のベースであるJIS漢字との間には当然字形差があり、校正上の調整に手間がかかることが想定された。そこで、翻訳原稿を「契沖」テキストベースで完全原稿に仕上げたうえで、文字処理は〔契沖JISコード〕⇒Unicode⇒〔文字鏡文字図形番号〕のテーブルでマクロによる一括変換処理をかけ、EPUBデータ上にJIS漢字では表現されない正漢字の図形をSVG画像指定の要素で入れることにした。ここでは文字文化協會が進めている『漢字基本図形表』編集過程の成果物である「通用字:基本字テーブル」を利用できたのが幸いであった。
ただ一括処理といっても目検による字形の確認が完全になくなったわけではない。例えば「弁」については「辧」「辯」「瓣」の使い分けがある。また、JIS3~4水準になるとプラットフォーム側(Kinoppy、Apple、Kobo、Amazon等)の実装フォントが、1~2水準ほど安定しておらず、結局精確な字形表現のために文字鏡文字図形番号で指定したほうが良いと思われるケースもあった。
また、EPUBデータ上では、文字校正のためにSVG画像指定した「1文字埋め込みフォント」の前後にいったん〓を挿入し、校正後〓一括削除の方法で校正作業の便を図った。
この手法によって、とりあえず各プラットフォーム端末に実装されているJIS漢字以外の文字についても、要求される文字図形で表示することができたのである。
SVG画像フォントの課題
SVG画像フォントへの依拠は、現時点ではまだいくつかの課題が残されている。
まず、「1文字埋め込み方式」であるため、各端末実装フォントとのデザイン差が生じる。基本的に本文はいずれも「明朝体」であるが、各フォントセットのデザインポリシーによる見た目の違いにより、埋め込まれた1文字との間にどうしても違和感が生まれるのだ。「文字鏡明朝体」はデザインより字形の精確な表現を優先し、また84画までの文字を表現するため、画数によって細身の印象を受けるのである。
文字文化協會では、文字鏡SVGフォントをEPUBコンテンツ内に1文字だけ埋め込んだ際、出来るだけ違和感が小さくなるような文字ウエイトの調整について検討を進めている。また、最近は「文字作成ツール」にも優れたものがあり、限られた少数の文字であれば、汎用的な図形番号を基礎にしたindexfont(今昔文字鏡プロフェッショナル版)の明朝体を字母として、埋め込み文字フォントの個々のデザイン的な調整を行うことも可能であろう。
また、データに文字図形番号保持しているとはいえ、通常のEPUB3がもつ「文字検索」機能が使えない点もネックである。もし字形的には異なるが代替可能な文字がUnicodeにあれば、それを「代理文字」として検索対象とする手法も可能性の一つとしては考えられるが、汎用的なEPUB3プラットフォームのサポートが必要となる。
また将来的に、WOF(Web Open Font)などの新しいフォント処理手法が、一般に利用される端末環境に実装されるようになれば、インデックスフォント研究会で検討が進められた「IFex」方式がひとつの解決手段となるが、実現のためにはまだ多くの課題が想定される。
いずれにしても多漢字の表現・印刷表示については、一意に文字図形を特定できる文字図形番号という汎用的な基盤を利用して過渡的な環境に適応しつつ、フォント処理、プラットフォーム等のさらなる環境の変化にも低コストで対応できる方策をとっていくことの必要性を感じるのである。
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(2)
黒田信二郎
『外字・異体字のバリアフリーを目指して』の電子化に取り組む
文字文化協會が最初にEPUB3をプラットフォームに選んで刊行した書籍がインデックスフォント研究会編集の『外字・異体字のバリアフリーを目指して―漢字研究7年の軌跡』(Kinoppy版)で、これは2013年に刊行した印刷書籍(紀伊國屋書店発売)を電子化したものである。
印刷書籍の組版データはDTPソフトEDICOLOR10を用い、文字処理は、JIS第1水準~第2水準以外の文字に「文字鏡TTFフォント」を埋め込み、該当文字について6ケタの文字図形番号を下付きルビとして振るといういささかユニークな方針を採用した。このことにより文字鏡がフォントを持っている、JIS漢字コードで一意に字形が表示できない外字や異体字、甲骨文字、変体仮名、梵字の印刷表示を実現した。
電子書籍では、この部分に「文字鏡SVG画像フォント」を埋め込むことにより、読者側の端末にゲタ文字や文字化けを起こすことのない、まさに「外字・異体字のバリアフリー」を実現したのである。EPUB3はSVGデータをサポートし、文字の拡大縮小にも対応する。またフォント実装仕様がJIS漢字(~JIS第3水準、第4水準)なので、各ビューワーが実装する漢字字形の揺らぎが殆どないので、一般的な日本語文章の漢字表記において「文字鏡SVG」に依拠するケースはかなり少なくなった。
電子書籍において、文字鏡SVG画像フォントは参照方式でEPUBデータに格納され、データ内に「文字鏡番号」が保存されるので、将来、文字コード・フォント実装環境に変更があっても、変換テーブルなどでデータマイニングが容易となるメリットも想定される。
また、印刷書籍では研究会が開催したセミナー、講演資料などを付録CD-ROMとして添付したが、電子書籍ではデータそのものを同梱した。
なお、「文字鏡フォント」のライセンスについては、製品である「indexfont 今昔文字鏡プロフェッショナル版」(CD-ROMで紀伊國屋書店から発売)を購入することで、フォントの商用利用と字母として利用するライセンスが得られる。
インデックスフォント研究会の研究成果
ここで、インデックスフォント研究会の設立経緯とその成果について、少しばかり触れておく。なお詳細は『外字・異体字のバリアフリーを目指して―漢字研究7年の軌跡』印刷書籍版または電子書籍版を参照頂きたい。
インデックスフォント研究会は2005年に、印刷、印刷機器、フォント、出版の業務に関わる関係者と文字鏡研究会の有志によって、入力・表示・印刷の業務で「クライアントの要求する文字を精確に表現できない文字処理の現場」の実態を把握し、そのニーズを分析してその解決策を探るために設立された。
【文字コードとフォント実装】
具体的には、コンピュータにおける文字処理の根底を支える文字コードと、フォント実装の問題であるが、コンピュータ技術・処理能力の進歩や、文字コードの拡張、例示字形の変更など、時間的経緯の中での変遷もあり、このことが問題を一層複雑にしていた。
文字コードの問題は、
・コードにない文字がある
・コードにはあるが、コードや例示字形の変遷により字形が変わる
・包摂があり必ずしも字形が特定できない
フォントの問題は、
・使用する機器や環境で、文字コードに対応するフォントが実装されていない
・インターネットが一般的になり、フォント入力・表示の環境が制作側で制御できない状況が生まれた
などで、
要するに文字処理のデジタル化により、関連するプレイヤーがシステムベンダー、フォントメーカー、規格情報の専門家、印刷会社や出版社など多岐に及ぶ一方、学術的な漢字研究の分野もあり、常に「現場がクライアントの要求する文字の印刷・表示にさまざまな苦労を強いられ、『外字・異体字』のためのコストを負担しなければならない」という実態が明らかになった。
【文字利用のTPOと現場の様相】
さらに、業務の現場ではそれぞれのクライアントの要求やビジネス上の様相が異なっており、業務形態別に把握することが必要とされた。
そこで、
・ビジネスフォーム印刷
・電子行政
・書籍出版
の各分野に分けて、それぞれ検討が進められた。
ビジネスフォーム印刷、電子行政の課題はもっぱら氏名表記の問題であったが、書籍出版の場合、一般書と学術専門書では必要とされる文字規模がかなり異なっている。実態を概略的に捕らえれば、一般書ではJIS漢字(第3、第4水準を含む約1万字)規模で収まり、学術専門書ではほぼ10万字程度の規模があれば収まると推測された。ただ、どの分野においても「クライアントの要求により区別しなければならない文字の印刷・表示」には際限がなく、標準化や行政効率上の観点からは「字形同定(異体字識別)ルール」についての検討が求められた。一方、歴史文化の観点では学術研究の深化の求めに応じ、将来にわたって文字規模の拡張が保証される必要があることも確認された。
【「文字図形共有基盤」の活用と「1文字ごとの処理」手法】
そこで結論として、当初から解決策としてその可能性を期待された「今昔文字鏡」がもつような、一定の識別手順によって区別されたあらゆる文字に、整理番号(文字図形番号)をふることにより、文字を図形レベルで一意に指定できる仕組みを「文字図形共有基盤」として確立し、関係者すべてが共有・拡張していく体制が望ましい姿として求められた。
一方、先述のように各業務の現場では、それぞれ要求される文字セットの内容や文字数の規模は必ずしも同じではなく、また、実務上の効率から膨大な「文字図形共有基盤」をすべての環境で実装する必要はなく、文字ニーズをTPOに応じて切り分け、コード・フォントの実装も必要な範囲に限り、例外的に発生する「必要な文字を1文字単位で提供する手段」をもつことで良いのではとの方向性も検討された。そして現在のコンピュータ技術環境において「1文字ごとの処理」に対応する入力や印刷表示の仕組みとして「SVG画像フォント」の活用に一つの活路を見出すこととなったのである。
「文字図形共有基盤」により、クライアントの要求するあらゆる文字の拡張が保証され、それが将来にわたって共有される環境が確立されることが実現して初めて、TPOが明確である環境において、そのニーズに応じた規模の文字セットへの「縮退」の議論ができるのではないかと考える。
電子書籍(EPUB3)での多漢字処理―編集制作の立場から(1)
黒田信二郎
文字文化協会の目指すもの
文字文化協會は、「あらゆる歴史的な文字遺産を電子的に表現することを目指して」活動し、その事業の一つとしてEPUB3をベースとした電子書籍の出版活動を進めている。それはすなわち、文字文化において、著者がどのような文字で表現していたか、そして出版印刷などの複製にかかわる編集制作者がその表現を尊重し、どこまで「原典と一致させる」こだわりをもつかという観点が、「表現の自由」、「歴史資料の保存・継承」に関わる、きわめて基本的で大切なことだと考えるからである。
デジタル環境の進化、変化は留まることを知らない。文字文化協會が行なっている出版活動におけるコンテンツの多漢字処理について、編集制作の立場からいくつかの経験を紹介していきたい。この記事を参考にして、ともかく何らかの形で「あらゆる文字遺産を電子的に表現する」取組みを受け継いでいっていただければ幸いである。
「文字」と印刷出版の現場の課題
まず、著者と読者の関係が、編集制作者を介在して出版印刷の現場でどのようなものであったかを振り返っておきたい。次の表は、主に「文字」コンテンツの著者・編集制作者・読者と複写表現技術のパターンを示したものである。
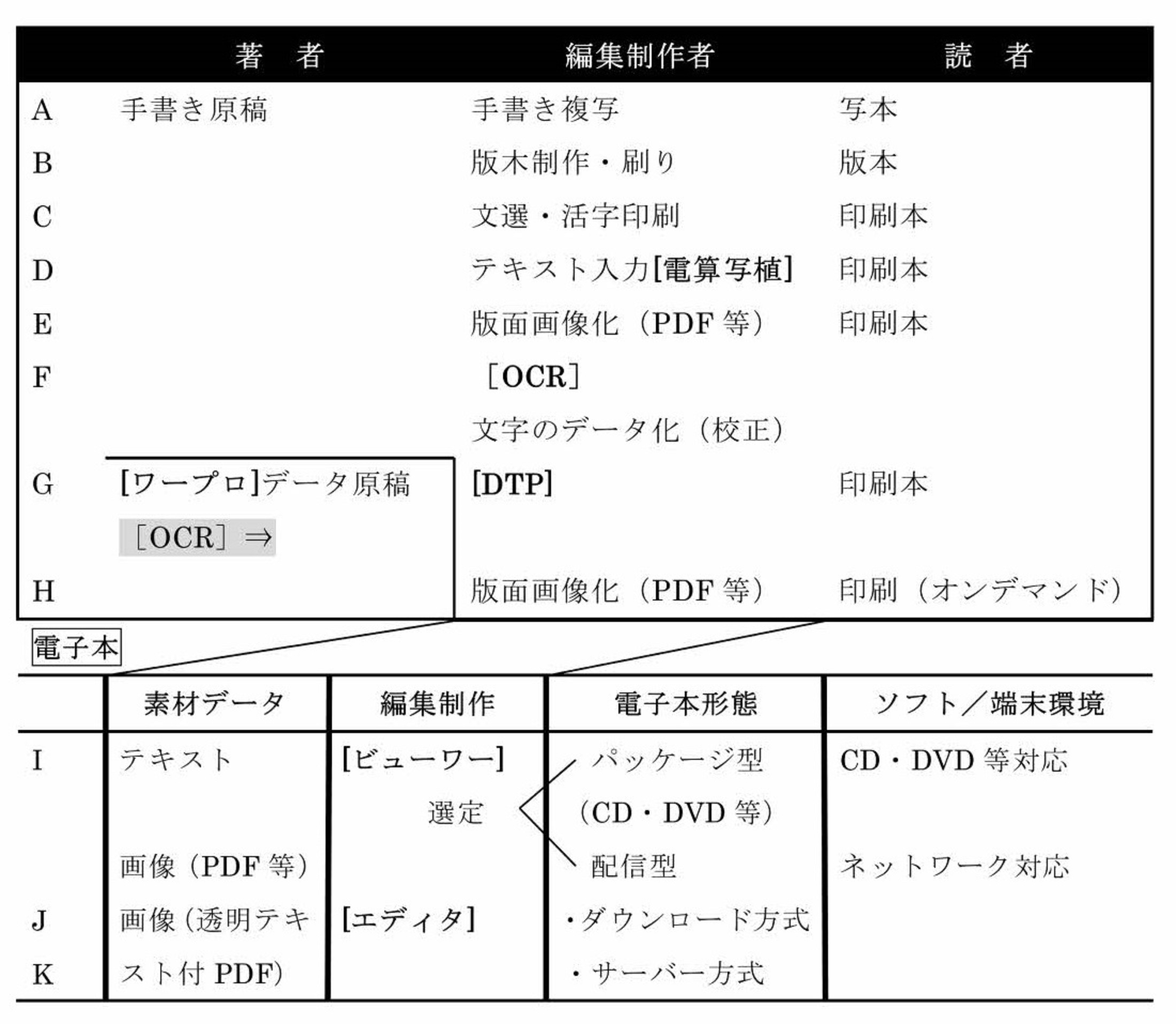
(注)
*電子本テキストの文字表現については、 [ワープロ][OCR][DTP] [ビューワー] [エディタ]等の各ソフトウェアが対応する文字コードとフォント実装の機器環境に依拠する。
*印刷本では、本文の組み方や装丁造本の設計が編集制作者の作業であったが、それが電子本ではどういうプラットフォームに乗せるかのビューワーの選定作業に代わった。
*電子本では著者が編集制作の作業を自分で行うことが容易になった。
読者にとって、写本・版本・印刷本においては「紙に書いてあるものを読む」ことであり、「より読みやすい版面」への技術的な課題はあるにしても基本的に問題はない。問題があるとすれば、「文字」についての著者の表現意図の尊重という点で、写本上の誤記や版木の彫り間違い、翻刻者の解釈や文選過程での活字選定などが想定されるが、それはまた、緻密な学術研究・議論のテーマでもあり、編集制作の立場からは「誤りであれ、表現しなくてはならない」すなわち「運用上区別する必要のある文字図形の存在」を認識することである。もちろん著者の明らかな誤りということもあるが、文字コードやフォントがないからといって「適当な文字に置き変えてしまう」ということに、編集制作者は十分な思慮をもつべきである。
なお「原典の尊重」ということでは、「読者の便宜をはかる」とした児童書における内容の改変や、「文庫化」で起きた「新字・新仮名に改める」ことについての議論もあるが、これは本論のテーマではない。
西欧のローマ字圏では、手書きの時代とワープロの時代の間にタイプライターがあったが、和文タイプはその文字の多さによって職業的利用にとどまった。日本語ワープロが出現して40年近くに及び、手書き原稿からデータ入力原稿に移行することで、原稿のデータ化を著者が直接行うスタイルが定着した。著者にとっては執筆の効率が格段に向上したことは間違いなく、また漢字の「コンピュータ処理」が漢字の世界の復元に貢献した面もきわめて大きい。しかしながら多様な文字・漢字の世界をデジタル環境で完全に表現するという、歴史・文化・伝統の尊重や学術的な要請に対しては、まだ多くの課題があり、文字コード、フォントを始め現在到達しているデジタル制作技術をさらに発展させるとともに、デジタルデータによる原典・資料保存の確実な展望を築いていく必要がある。
原典・資料保存媒体の歴史とデジタルデータ
原典・資料は長らく紙媒体の形態で保存・維持が図られてきた。「紙」は羊皮紙やパピルスの時代から辿ればギリシャローマ時代からの筆記媒体であり、その保存には歴史的な実績がある。しかし19世紀半ばから工業化に伴う紙の需要に応じて大量に製造されるようになった「酸性紙」は、製造から50年~100年間程経過すると劣化し、ぼろぼろに崩れてしまうことが明らかになった。この問題は「本」を大量に収集し、長期間保管する使命を持つ図書館で特に問題視され、1970年代頃から欧米諸国を中心に「酸性紙問題」として社会問題となった。
その解決策の意味もあり、マイクロ媒体による複写保存も広く行なわれてきた。マイクロフィルムは、現在、長期保存の条件が国際標準として規定され、期待寿命は500年以上とされているが、これも保管環境、取扱い・修復、作製時の処理・材質が不適切であると劣化する。保管庫から出して見たら「フィルムが酢昆布のようになっていた」という事件も話題となったが、フィルムの素材と現像処理、保管環境について常に注意を払う必要があるとされる。
その後、コンピュータ技術が発展し、驚異的な処理能力の向上により大量の記憶媒体容量が確保できるようになり、デジタルデータでの保存が現実のものとなった。しかしCD-ROMやハードディスク等の電子媒体は物理的な劣化や故障により記録された情報は再生不能になる。また記録媒体や機器のハード面やOS・ソフトウェア・データ形式などのソフト面の技術的進歩により、逆に長期的にはデータの再生が難しくなるという懸念もあり、新システムと新媒体への移行(マイグレーション)は維持保存の体制とコストの面で大きな負担になる。したがって現時点で「世紀」を超える長期保存維持が保証されるものではない。
しかしデジタルデータは、検索ができるというメリットとネットワークを利用した多角的広域的な利用が可能であり、その活用という面で計り知れないものがある。やはり原典・資料のデジタル化を進めながら、「原典の尊重」「長期保存」の視点から想起される個々の課題の解決を図っていくべきであろう。